而且學到更多以前聽過卻沒學過的實用技巧!
Codeforces Round #291 (Div. 2)
A: (頹題, Greedy)
又一題改digit 令數字變成什麼什麼的題目...我又再重覆上一場的句子: 通常都是Greedy就行了..
B: (Math, Geometry)
略有一點難度的數學題, 問最少要多少條線才能把所有目標都擊破
也不用特別的技巧或用上大家比賽常用的Geom的Class, 只要計Slope, 一樣Slope 的就Lie on 同一條線了...
C: (String, Hashing)
第一題要詳細記下的題目!
這題跟之後會寫的String Searching不無關係!
先來說題意吧: Given n 條pattern, 和m 條 string (每一條是一個獨立query), 所有string 只會由[a-c] 組成
問是否有任意一個pattern跟 string 只差exactly 一個字母相異?
在學了Trie的基本之後的我, 直接想到的也是用Trie 去解, 事實上看comment也有人說能用
prefix tree (即是Trie)去解...但當時我沒很直接想到怎樣做
String的處理我一向都很弱 (說真的也沒什麼特別強=.=)
我只想到 每個query 可以試住做以下的事:
- 每個位試試改成其它的2個字母 eg: 原本是'a'的話試試改成'b'或者'c', 每個位都這樣做
- 跟每個pattern比較一下看是否一樣
所以這樣說吧, 上面的第一步最壞的情況已經是O(L), 第2步要跟每個pattern比較一下這步卻很痛苦, 這是multi-pattern matching, 用KMP好像也不一定夠快? (我也忘了KMP怎寫, 只記得concept...) 實際上我也真的這樣implement, 也真的超時了
結果還是跑去看Editorial, 又掘到金了! 兩大keywords:
這個Wiki 的解釋也真的很好懂, 沒複雜的分析, 但很有說服力, 而且還說明了它跟其它String Matching算法的分別, 例如它說了 "Rabin-Karp始終是Hashing, 可以有很差的效率, Single-Pattern Matching上還是KMP佔優, 但它的強處是在Multi-Pattern Matching (其它的還有AC自動機)"
所以...基本上這題就是Rabin-Karp Algorithm的變種囉
詳細的自己再看上面的wiki-page吧
Rolling Hash 是一個技巧, 不一定要 "減頭加尾", 像這題, "換一個字母" 這類的事當然也做到
只要你是用Polynomial Hashing就行了
我想這題最難的是要說服自己時間複雜度
官方說是 O(L lg n) 我感到有點奇, 因為我自己AC的版本, 最低限度也是O(L lg n) 但這沒算上Hashing Collision後要做String Comparison 然後fail 這件事
理論上Hashing Function柒的話, 這件事可以發生很多次吧? 那就遠超於 O(L lg n)了, 因為要做很多次String Comparison, 這也是為什麼它用在Single-Pattern Matching時worst case可以跟naive algorithm一樣是O(NM)的原因...不過算了AC了就好了, 也可以這樣想吧: 一直以來所有人都是用Polynomial Hashing去比賽的, 這已經是定式了, 自然不會是一個"柒"的hash function...
以某黃字User的comment做一個結語:
強烈建議看一下Code, 也是很有機的寫了一些comment
http://codeforces.com/contest/514/submission/10158032
D: (Binary Search, Two-Pointer Algorithm, Segment Tree)
這題有點難搞
原因在於 題意其實很直觀, 就是不斷query 一個range maximum
所以我直接就用Segment Tree上了! 結果也是AC的
(原本有想過能否用BIT可以更易寫出來, 但maximum之類的好像不能用BIT做...只能做統計的工作啊)
http://codeforces.com/contest/514/submission/10172455
正如我的comment上所說, 這是overkill啊,
官方的答案是用一種叫 "Two-Pointer Algorithm" 的方法, 那個方法應用在這條題目上很高明
但實作上我自己是想不出來了, 紅字User們說是用兩個Stack的樣子
總之正解是易寫也很有效率
我反而學到了兩件事: 是否overkill也不要緊, 但起碼concept對, 寫得出來, 就可以AC的, 也不用這麼介意...
然後再來Google了一下什麼是Two-Pointer Algorithm...這東東很多題目都有Tag, 從來都沒認真想過是什麼的一類Algorithm
看了高手們的解說, 就比較清楚了:
這類Algorithm的運作通常是這樣的:
一個pointer指住第一格, 一個pointer 指住最後一格, 然後開始夾三文治
做某些東西或者checking, 然後移動其中一支pointer (不知會否有2支一起動的情況?)
一個pointer只能向單一方向移動, 而每次最少一定要移動其中一支pointer
這樣的話 時間性一定是O(N)了
這類Algorithm好像很強大的樣子, 形象化來想有點像什麼Sliding Window還是 Sweeping Line的? 傻傻搞不清, 總之這種思路還是記一下好
E: (DP, Matrix Repeat Squaring)
另一題很想記下的題目!
因為這道題的重點在於當年聽過的Matrix Repeat Squaring應用
話說當年完全不知 "為何, 何時, 怎樣" 用這個技巧
還是CF的高手們好, 一個Reference就解得清清楚楚的說
先說一下題意:
一棵無限的Tree, 每個node 都一樣有同一set的兒子 (最多有10^5個兒子)
eg: root 有 3個兒子, 它的每個兒子也一樣有3個兒子....直到無限深度
每個兒子跟它的parent距離 (edge的長度) 最多是100
現在問有多少個node距離root 是 x ( x < 10^9)
這題很直接就能寫下DP的狀態:

dp(i) 為 有多少個node 距離現在的node EXACTLY = i
然後答案就是

但難度在於 dp(x) 的 x 可以有 10^9 那麼大! 即使是 O(N)也超時 (也超MEMORY!)
怎麼辦呢??? 原來....原來....
原來這種情況就是要用Matrix Multiplication的Trick啊
在Editorial 挖金挖到一篇超上乘的tutorial 給我這種新手的
Matrix Exponentiation
而這就是 "Matrix Repeat Squaring" 出場的時候了!
這種加速的技巧只能用於符合某種"形式"的 Recursion Formula, 也就是DP Transition
Rolling Hash, Rabin-Karp Algorithm前者是一個運用Polynomial Hashing的一個技巧, 後者是活用這個技巧的 Multi-Pattern Matching Algorithm!!
這個Wiki 的解釋也真的很好懂, 沒複雜的分析, 但很有說服力, 而且還說明了它跟其它String Matching算法的分別, 例如它說了 "Rabin-Karp始終是Hashing, 可以有很差的效率, Single-Pattern Matching上還是KMP佔優, 但它的強處是在Multi-Pattern Matching (其它的還有AC自動機)"
所以...基本上這題就是Rabin-Karp Algorithm的變種囉
詳細的自己再看上面的wiki-page吧
Rolling Hash 是一個技巧, 不一定要 "減頭加尾", 像這題, "換一個字母" 這類的事當然也做到
只要你是用Polynomial Hashing就行了
我想這題最難的是要說服自己時間複雜度
官方說是 O(L lg n) 我感到有點奇, 因為我自己AC的版本, 最低限度也是O(L lg n) 但這沒算上Hashing Collision後要做String Comparison 然後fail 這件事
理論上Hashing Function柒的話, 這件事可以發生很多次吧? 那就遠超於 O(L lg n)了, 因為要做很多次String Comparison, 這也是為什麼它用在Single-Pattern Matching時worst case可以跟naive algorithm一樣是O(NM)的原因...不過算了AC了就好了, 也可以這樣想吧: 一直以來所有人都是用Polynomial Hashing去比賽的, 這已經是定式了, 自然不會是一個"柒"的hash function...
以某黃字User的comment做一個結語:
Most hashes are certainly not unique or why do we use hash? If C is in ACM/ICPC, you can simply choose a prime other than 3 because the problem setter does not know which prime you used so he can not construct data against you. He can only guess some contestants will choose 3 and build some data to make them failed. However, in Codeforces, hackers can construct data against a solution. So you have to compare two strings themselves when the hash of them are the same. However the probability of two different strings have same hash is low so only a few strings will be compared. So, the hash helped you to evade TLE.
強烈建議看一下Code, 也是很有機的寫了一些comment
http://codeforces.com/contest/514/submission/10158032
D: (Binary Search, Two-Pointer Algorithm, Segment Tree)
這題有點難搞
原因在於 題意其實很直觀, 就是不斷query 一個range maximum
所以我直接就用Segment Tree上了! 結果也是AC的
(原本有想過能否用BIT可以更易寫出來, 但maximum之類的好像不能用BIT做...只能做統計的工作啊)
http://codeforces.com/contest/514/submission/10172455
正如我的comment上所說, 這是overkill啊,
官方的答案是用一種叫 "Two-Pointer Algorithm" 的方法, 那個方法應用在這條題目上很高明
但實作上我自己是想不出來了, 紅字User們說是用兩個Stack的樣子
總之正解是易寫也很有效率
我反而學到了兩件事: 是否overkill也不要緊, 但起碼concept對, 寫得出來, 就可以AC的, 也不用這麼介意...
然後再來Google了一下什麼是Two-Pointer Algorithm...這東東很多題目都有Tag, 從來都沒認真想過是什麼的一類Algorithm
看了高手們的解說, 就比較清楚了:
這類Algorithm的運作通常是這樣的:
一個pointer指住第一格, 一個pointer 指住最後一格, 然後開始夾三文治
做某些東西或者checking, 然後移動其中一支pointer (不知會否有2支一起動的情況?)
一個pointer只能向單一方向移動, 而每次最少一定要移動其中一支pointer
這樣的話 時間性一定是O(N)了
這類Algorithm好像很強大的樣子, 形象化來想有點像什麼Sliding Window還是 Sweeping Line的? 傻傻搞不清, 總之這種思路還是記一下好
E: (DP, Matrix Repeat Squaring)
另一題很想記下的題目!
因為這道題的重點在於當年聽過的Matrix Repeat Squaring應用
話說當年完全不知 "為何, 何時, 怎樣" 用這個技巧
還是CF的高手們好, 一個Reference就解得清清楚楚的說
先說一下題意:
一棵無限的Tree, 每個node 都一樣有同一set的兒子 (最多有10^5個兒子)
eg: root 有 3個兒子, 它的每個兒子也一樣有3個兒子....直到無限深度
每個兒子跟它的parent距離 (edge的長度) 最多是100
現在問有多少個node距離root 是 x ( x < 10^9)
這題很直接就能寫下DP的狀態:
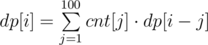
dp(i) 為 有多少個node 距離現在的node EXACTLY = i
然後答案就是
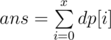
但難度在於 dp(x) 的 x 可以有 10^9 那麼大! 即使是 O(N)也超時 (也超MEMORY!)
怎麼辦呢??? 原來....原來....
原來這種情況就是要用Matrix Multiplication的Trick啊
在Editorial 挖金挖到一篇超上乘的tutorial 給我這種新手的
Matrix Exponentiation
But, what will you do if the problem says, given 0 < n < 1000000000, find f(n) % 999983 ? No doubt dynamic programming will fail!這是它的前言, 說了最簡單的DP例子Fibonacci Sequence, 在 n 好X大的時候也是會吃屎的
而這就是 "Matrix Repeat Squaring" 出場的時候了!
這種加速的技巧只能用於符合某種"形式"的 Recursion Formula, 也就是DP Transition
| f(n) | | f(n+1) |
| f(n-1) | | f(n) |
M x | f(n-2) | = | f(n-1) |
| ...... | | ...... |
| f(n-k) | |f(n-k+1)|
直接引用它的解說, 其實就是先寫下 類似以上的算式, 以他的notation
第一格就是我們想要的答案 而其它的是計算答案時要用上的東東
然後我們逆算出 M 這個 n*n 的matrix, 之後的就簡單了, 把repeat squaring的技巧用在
matrix multiplication 上算出 M^x, 乘上我們的"base case" (最開頭的 n*1 vector)
就能得出我們想要的答案 (右邊的n*1 vector, 的第一格)
例如 Fibonacci Sequence, F(n) 要用上F(n-1) 和F(n-2) 對吧
右邊先寫上 B
| F(N) |
| F(N-1)|
左邊是比它"前一步"的States, 我們叫它A:
| F(N-1)|
| F(N-2)|
然後要做的就是人手逆推 M, 使 MA = B
| ? ? | |F(N-1)| | F(N) |
| ? ? | * |F(N-2)| = | F(N-1)|
不難推出 M 是
| 1 1 |
| 1 0 |
那麼當我們要算 F(10^9) 的時候
只要算 M^(10^9) * A , 然後得出的B 的第一格就是我們的 F(10^9)了!
其它詳細的看那個優美的Reference吧, 都說得很清楚了, 通常M 都會很有Pattern
不需要hard code就能generate出來的
由於 是做 lg(x) 次 matrix multiplication, 假設matrix 是 N*N
那麼就是 O(N^3 * lg(x))
很好很強大的DP輔助技巧!
回到原題目上, 基本就是用這個想法, 當然作為Problem E也沒這麼直接
最不同的是我們要求的答案不是單一的 DP(X) , 而是 summation DP(i)
但也是大同小異的
首先注意到我們的A (也就Base Case的vector) 要用上全部DP(100) 個State
所以 X <= 100的時候, 直接用普通的DP就好了
當X > 100的話, 我們就要用上這個技巧了
注意先Update X = X-100, 因為現在我們的"Base"不是 0, 而是100
然後由於我們想要算的是 summation DP(i)
那麼乾脆把它放進我們的A (還有B) 內 加上本來的 DP(1) to DP(100) 總共是一個
101 * 1 的vector

官方的notation是 1* 101的, 思路一樣, 我想我以後還是會跟Reference那個notation
接下來的就是逆推 M了, 這一步是這一題的唯一難度 M 是什麼可以自己看Editorial:
(注意它跟我 / Reference的notation不同, 應該是Transpose了還是怎的)
(注意它跟我 / Reference的notation不同, 應該是Transpose了還是怎的)
就是這樣了!
最後把AC的Code貼一下以作記念: comment應該也算清楚的 日後重溫應該也明白的吧...
http://codeforces.com/contest/514/submission/10218534
http://codeforces.com/contest/514/submission/10218534
沒有留言:
張貼留言