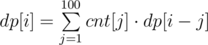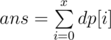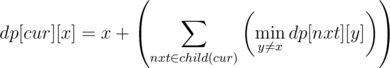說好的Facebook Hacker Cup 2015, 終於有空寫了
事實上在前幾天才做完四題...
FB的比賽很不好地沒有practice mode 幸好偉大的CF以Gym的形式提供了練習途徑
Gym在沒有AC前不能看Test Cases 和 別人的Code就是了...
這場比賽有4道題目, 難度我覺得是CF 較難一點的Div. 2 吧..?
比賽使用計分制, 實際執行時間也有幾分鐘, 這是我一直在想的問題
因為大部分比賽只用1秒, 算法也比較易逆推出來
數分鐘的話反而很混亂, 好像什麼 "不正常" 的算法也有機會是官方的答案...
即場我只做了2題, 而規則上所有跟第500名同分的人都可以去Round 2
沒想到遠超過500人4題全對了...
我交的2題也只AC了1題, 另一題錯了一個白痴的exceptional case...唉!!
還有另一題沒有做的, 其實不是難做, 是語癌的問題, 直到現在我也搞不清楚是我英文差還是什麼原因, 總之完全不明白題目的意思, 跟Test Case怎樣理解也有點矛盾, 即使AC了也是半合理地
推斷"題目是這個意思"...這個有多少生氣跟遺憾
最後一題則是看了答案後更加知道沒有抵賴的餘地, 現場是怎樣都不會做到的, 主要原因是...算法是想到了, 倒是算法的parameter limit 我完全沒有頭緒, 暴試的話怎樣也會超時...
所以即場我是"打倒自己", 感覺那個算法是錯的, 有其它方法....原來方法是對的, 倒是有聰明的想法證明parameter limit很小...
2015 Facebook Hacker Cup, Round 1
題目:
http://codeforces.com/gym/100579/attachments
A: (Math)
Given range [A,B], B<=10^7, 問有多少數的primacity = K, K<= 10^9
primacity的定義是 # of distinct prime factors
這題算很易了...就是改一下Prime Sieve (就普通的Prime Sieve, 不用前文所說的Linear Sieve)
每次刪去合成數時把該合成數++, 代表這個合成數又多一個prime factor了
是我唯一現場AC了的題目...
void make(){
p[0] = p[1] = 1;
for(int i=2; i<10000005; i++){
if(!p[i]){
for(int j=i; j<10000005; j+=i){
p[j]++;
}
}
}
}
B: (String, Trie, STL)
正是我說的語癌題!!!
其實看時已經知道是用Trie / 字典之類的方法做了, 數據量問題不太肯定能不能用STL做
事後知道是OK的, 但我也說了想借此機會也應用一下Trie, 就用Trie做了
這題沒難度的...只要理解了題目的話!!!
題目大意是: 給定一堆字, 現在想把它把儲進電話內做autocomplete. 那麼當然是打該字的prefix就ok了, 然後問最少total打多少字....重點的一句是這樣的:
The prefix must either be the whole word, or a prefix which is not a prefix of any other word yet in the dictionary.
媽啊, 你UP咩春呀...
最開頭也直接的想法是: 啊, 當第某一個prefix已經儲進去了, 之後就不能再以同樣的prefix代表這個字了
這樣的解釋連第一個test case也過不了, 因為要是這樣, 第4個字的prefix就是 "hi" 不是"hil"
那麼...是不能跟已經儲進去的prefix所代表的那個字一樣嗎? 然後
either be a whole word 又是怎樣, 是說整個字都是另一個字的prefix要特別處理嗎??
靠, 怎樣想也不能同時滿足所有test case, 尢其第3個
而這樣導致的結果是, 我知道是用Trie做也無從入手....語文能力是多麼重要啊...
好吧, 開估吧, 以下是正確的題目意思:
每次加一個字進字典時, 盡量加最短的prefix, 但這個prefix 不能是前面其它字的prefix!
所以sample test case 1 第4個字不能入"hi"! 因為第1個字已經是"hi", 即使第一個字儲進電話的prefix是"h"而已也不行!
然後test case 3 答案是11 並不是我原本想的 "4+3+2+1+1"...而是"1+4+3+2+1"!!!
解釋是第一個字當然就入一個字母的prefix "a", 然後第2個字, 不論怎樣切都是第一個字"aaaaa"的prefix, 所以就只能以"whole word", 也就是"aaaa"這樣加進電話...之後的字也一樣
他媽的, 明白題目是這樣之後就是直接應用Trie了...我也知道我第一次寫Trie
但的確是直接用而已...你媽的語癌題目
有關Trie的理解跟應用 (以及其它String Matching的Algorithm) 我打算另開一篇詳寫, 因為近來很巧的做了兩場CF也有兩題題目學到新東西了...
這題一句, 用Trie! 每次加字就一個個字母插進去...一發現還沒生成該node 就是前面沒有相同的prefix了...采用之!
另外如之前說的, 這題用STL的Map 好像也行, 其實重點還是題目的理解啦...
C: (DP, Combinatorics)
第二題即場有交的題目...而且是"正確"的!!!
我只是沒有處理一個特殊的Base Case而已...而且那個Base Case也是反直覺得很嘛...
老實說Download完input file後我也有特別留意這個Case, 反而我是認為我的output對才提交的呢...
題目有點複雜, 給了一個體育比賽的完結分數, 例如 3-1
代表第一隊以3分勝出, 第二隊拿了1分, 就輸了
然後定義一種叫
"無壓力勝出", 是說勝出的隊先拿了第1分, 然後一直到完結它的分也比另一隊高!
另一種叫
"無限壓力勝出", 是說勝出者直到敗者達到它的完結分數之前, 一直也比敗者隊低分!
問題是數出有多少種不同的組合可以"無壓力勝出" 及 "無限壓力勝出"?
簡單來說, DP, 而且是2個DP, 2個互相很像, 沒有交集
無壓力勝出較易數的, 另一個因為敗者到達結果分數後你可以反超前, 較難數, 但也大同小異
詳細就不寫了, 也不太記得了, 直接貼Code...
而我中的伏是...是...是敗者0分的情況..? 好像是...不太記得了
總之是一開始敗者已經到達完結分數, 這樣的情況下組合只有1, 而我的DP出0了...
真的只差這一個Case, AC與WA之差....!!!!!!!
dp[1][1] = dp2[1][1] = 1;
for(int i=2; i<=a+b; i++)
for(int j=1; j <= a; j++){
dp[i][j] = dp[i-1][j-1];
if(2*j > i) dp[i][j] = (dp[i][j] + dp[i-1][j])%C; //無壓力勝出
}
for(int i=2; i<=a+b; i++)
for(int j=1; j<=b;j++){
dp2[i][j] = dp2[i-1][j-1]; // 有壓力勝出
if(2*j >= i || j == b) dp2[i][j] = (dp2[i][j] + dp2[i-1][j])%C;
}
printf("%I64d %I64d\n", dp[a+b][a], !dp2[a+b][b]? 1: dp2[a+b][b]); //特別處理中伏CASE
D: (DP, Graph)
最後的一條好題目...
只能說我輸了
題目很簡單的, 給了一棵Tree, size N <= 200,000
要color這棵樹, 但每個node不能與它的parent一樣color
color 由 1開始到 N, 無限量使用, color i 花費 $i , 問total 最少多少錢才能完成coloring?
當時還沒學到Bipartite Matching, 但當然現在直接就會想到, 2-coloring吧?
但很明顯沒這麼簡單的...
看官方FB的Solution, 2-coloring不一定是最好的吧...
這種Tree的題目, 很易想到DP去, 但先慢慢想一下
最初想的, 會否有Greedy的水分在內... (因為是Round 1...這個心態真的要改, 害死我很多次)
Greedy來說, 會否由根一直把能填最小的都填, 又或者由葉一直填上根?
很可惜的 我自己也找到一堆反例子
在一直寫反例子的途中, 有個感覺, 就是可能會使用到的color數目不會太多...但證實不了
結果這就是問題的重點...我當時想到的是, 既然Greedy好像不行, 只能DP了
設DP(x, c) 為 node x 使用 color c 時, 以它為根的subtree 的minimum cost
問題是c 實在可以太大了, 可以到N 啊...
那時我的確沒想到, 也想不到, 如果 c 很小, 其實問題就解決了...
也就是說...!
這個DP是正解, 讓我來貼一下CF高手們的答案
也沒什麼好解釋的, 有點self explain, 感覺就一定對的了....
所以這題最後一題的難度是在
證明 c 很小啦!!!!
官人來看, 小的找到兩個不同的方法去證明...一個簡單易明但有點出cheat的, 另一個是官方FB的嚴謹數學證明!
先來看簡單易明的Version:
由某CF高手提出, 我們想要證明的是
會用到的不同color種類很少, 這個數字跟Tree Size N 有關係。
有點逆向思路, 來定義一個function C(x):= Root node一定要使用color x的話, 達成的minimum cost 的Tree的minimum size. 有點語癌, 其實不難明, 看頭幾個數字:
C(1) = 1, 代表的是只有一個node的Tree, 它能達成最minimum cost就是1, 也是我們的x
C(2) = 2 對嗎? 因為 root 使用 2, 它的獨生子用 1....很可惜這是錯的
C(2) = 3 才對!! 因為我們希望這是
唯一的樹, 它是最小的, cost也是最低的, 然後root 一定要使用 2, 所以就是 root使用2, 兩個兒子用1, 這3個node的color怎樣變也不會比這個填法更優
而如果只有獨生子, 則那個樹不是唯一的, 因為也可以root 用1, 獨生子用2, 同一個size, 同一個cost, 但root 可以不使用 x=2 為color
C(3) 開始複雜了, 直接套用該高手的話:
root要是3的話, 它最少有3個color 是1的兒子, 不然可以把全部color 1 的孩子(最多2個) 變為 2, root改為 1, 導成相同的cost相同的size...
同樣道理, 它最少有 2個 color 是2的兒子
那麼C(3) 最少是 1 + 3*C(1) + 2*C(2) = 10
小總結, C(1) = 1, C(2) = 3, C(3) = 10....怎樣, 有點Pattern / Sequence的感覺吧??
然後高手說, 把這個數字去OEIS找一下, BOMB! 出現鳥!
Number of order-consecutive partitions of n
1, 3, 10, 34, 116, 396, 1352, 4616, 15760, 53808, 183712, 627232....
這個當年KN介紹的神網想不到在這兒能夠用上...
那麼廢話就不多說了吧...實際上 c 去到 ~11-12, 最小的樹已經超過200,000個nodes...
也就是說我們的DP是可行的, 也就 O(N*c)而已! |
下面是FB官方的數學方法:
We can also prove that O(log N) is an upper bound for C. Let C(k) be the size of the smallest tree that needs all colors 1, 2, ..., k in an optimal coloring. Trivially, it holds that C(1) = 1 and C(2) = 2. Without loss of generality, we can pick the node with color k to be the root. In that case, the root needs to be adjacent to all colors from 1 to k-1 and we can apply the inductive hypothesis as follows:
C(k) ≥ C(k-1) + ... + C(2) + C(1) + 1 ≥ 2k - 1 + ... + 21 + 2 + 1 = 2k
這...這個是傳說中的M.I. 啊...思路是直接猜想 c ~ O(lg N), 逆向只要證明到上面那句statement就ok了...我說我真的不能即場就有這麼嚴格的證明啊..
CF另一些高手的思路想像, 卻更像是比賽中可以學習使用的想法:
I think there is: a[1] = 1
a[x] = 1 + 2 * (a[x - 1] + a[x - 2] + ... + a[2] + a[1])
At least 2 v values must appear in children. If there is only one v < x value, you can swap it with root and you have v in root.
So a[x] = 3x - 1 I assumed second y < = 13.
思路是一樣的, 也是很roughly地寫出 color = x 的root 下面最少要用多少個兒子
然後不用直接找lower bound, 但upper bound已經是 O(lg N) 了....這個思路也真的要學習下
順帶一提, FB官方也有說到這題有O(N)的解法, 解法很巧妙, 我不知怎樣實現就是了
大約就是不用把10多個color暴試, 只要試"最好"的2個color就好了
然後precompute 最少要給多少錢, 然後看看那些node要將就使用"第二好"的color 就把它加上那一個offset...詳細自己看官方答案:
https://www.facebook.com/notes/1047761065239794/
我是不知道怎樣找出"最好"的2個color就是了...
來個小總結, 這是一場學到很多東西的比賽, 而且只是Round 1, 了解到自己實力很不足啊
以前的話應該會很不開心吧, 現在好像沒那麼介意了, 還有點小開心可以繼續進步學習挑戰, 我想我是瘋了 0.0