2015年大年初一
還是先把要做的做完...就是把解題過程記下..
這場是"回頭"打的#287, 所以上一篇先記下#289...
#286也有做的, 可是該場較特別...下篇再記 (順序什麼的先不管了=.=)
Codeforces Round #287 (Div. 2)
雖然這場也是5題做完..可是這場比較特別, 在於題D我卡了好幾天, 最後的最後才發現自己中伏了...然後也好不容易才AC的...題E相對下還易很多呢..起碼是短時間內自己過的...(雖然是某個圖論的白痴東西弄到錯了很久..)
D跟E也要花點時間說呢 zzz...
A: (Greedy)
一題赤裸裸的Greedy...沒什麼好說的
B: (Math, Geometry)
這題比較令我出奇地覺得原來Div 2的題B也可以這樣啊...然後才發現原來也是很直觀的說
分類上絕對是Geometry, 但Geom也是Math的一部分, 也就標上Math的Tag好了...
上圖就是題B的題目, 就是給定一個圓形, 然後在邊上任意一個點作pivot, 然後該圓形可以繞住pivot轉一圈, 這樣算一步。問要多少步才能使圓心由原本的位置轉到目標的位置?
這類的題目很自然一想就會想到Shortest Path, BFS 之類的東西...
拉上Geom也好像很複雜...
但是只要在紙上畫兩畫, (或者腦子強的空想一下真實的情況)
不難發現一步之後, 圓心的軌跡 (Locus) 很有趣...
(Locus 是不是這裡正確的用語? 我也不太清楚, 只記得中學時老師說過Locus已經不再考了, 但我想一定是個很有用的道具吧...)
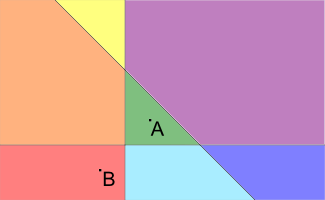
看我上面漂亮的小畫家圖...
黑色是原本的圓形, 紅色是繞住pivot 轉動時的圓形位置, 然後籃色虛線就是圓心的"走向"
也就是圓心的Locus
然後這只是假設pivot是定在那個點的情況, 實際上pivot可以在黑色圓形的邊上任意一點
發現到Locus也是一個半徑一樣的圓形, 而圓心剛好就是pivot位置
結論就是在任意選pivot的情況下, 圓心的Locus是以黑色圓形的邊任意一點作圓心來畫圓形的Union
按上圖來想像一下, 就是有很多藍色的圓形, 一個疊一個的, 組成了一個跟原本圓心一樣, 兩倍半徑的圓形
總結一下的話, 就是在一步內, 圓心可以移動到一個兩倍大的圓形範圍內任意位置
這樣的話, 到目標點的最少步數就很易找了....就是拉直線然後Greedy地一直走過去吧
實際上可以寫成公式, 所以是O(1)
C: (Graph, Tree, Ad-hoc)
一題很奇怪地不知怎麼被人Tag為Math的題目, 後來看Editorial才知道我的解法不是官方的
好像是跟某堆User一樣, 是O(h)的解法, 比官方的好一點...
題目有點Counting的意味, 給定了一系列的instruction, 基本就是, 由根點不斷"左右左右..."地向下走, 直到葉就回上一層...然後問, 要到達某一個葉子前, 會先經過多少個nodes?
這題我的解法是很簡單的逆向思路...
首先由終點向上走...會發現一個很單純的事實:
如果終點是 RIGHT CHILD, 那麼在上一層時的instruction一定要是"右"
LEFT CHILD的話就是"左"
那麼要是在instruction 必需要是"右" (才能到達終點) 時的instruction, 不巧是"左"的話
很自然地該點的所有左子孫都會經過....關於這點我沒有很詳細的思考過程, 反而是有一個
很人性化的想法說服了自己: 要是該點的左子孫內有點不會經過的話, 那麼要是問題的input是裡面的其中一個葉子怎麼辦? 題目也沒說明沒有solution時要怎麼做...就是說每個葉子都可以自然走遍的....很有說服力吧=.=
回到問題上, 這樣思考的話就是說: 由根點開始走到目標點的路只有一條 (Tree...)
我也清楚知道這條路的走法 (eg: "左左右左右右左右...")
然後我也知道instruction是"左右左右"不斷loop的, 那麼當一個instruction跟我要走的路需要的instruction不同的時候, 就是"走錯路", 而走錯路是必定會經過下面所有子孫, 才會回到該點, 然後就走回正路去下一層...一直到終點
這樣算法就很簡單了: 先找出由根點到終點的路線, 然後以O(h) 的Loop, 試住左右左右的走下去,要是"走錯路"的話, 就把答案加上"錯路"的sub-tree size, 由於是full binary tree, 不用precompute也可以, 最後把答案加上 h-1, 因為根點到終點的路本身就會經過h - 1 個點啊...
D: (DP, Combinatorics)
題目簡單卻陰濕 (其實是我低能...), 答案很難寫...起碼我看過別人的code, 也不是很直接就寫完的DP...
題目是這樣的:
求符合以下條件的數字總數目 mod m
該數字要有n 個位 (沒有leading zeros)
該數字要有suffix y, y > 0, y % k = 0
n,k,m 也是input, n <= 1000, k <= 100, m <= 10^9
要說的話, 這題最直接想到的也是直接的DP做法
State就是這個吧:
State(L, r) := 長度為L的數字而 mod k 之後剩 r 的數字數量
這樣也只有1000 * 100 個State, 很有DP的樣式
問題在於, 怎樣數呢? 做過一些Combinatorics的題目也會知道, 怎樣去防止repeat counting絕對是重中之重, 只要這個搞定了, 其它也只剩簡單數學 / implementation技巧而已...
然後這個開頭我是難倒了, 甚至完全想錯方向, 不知怎的竟然走去想 inclusion-exclusion principle了...
事實上是很簡單的...在於這題的context上, 不要重覆數的同義解釋是, 用長度為L的suffix數出來的, 跟長度為L' 數出來的要不交集 (L' > L)
就是說在算 State(L', 0) 的時候, 我不可以算一些由 State(L, 0) 來的數目
也不是直接 State(L'-1, r), r > 0 就可以的, 因為這個state也可以包括來自某些State(L,0), L' -1> L 的數目...
想到這兒, 自然就會想到在算任何的State時, 也不要用上 r = 0的State...這兒會發現這題用bottom-up / iterative 的寫法絕對更易想/寫
以iterative的想法, 一個State(L,x) 轉移去另一個State(L+1, r) (我較喜歡用"生成" 另一些States) 的physical meaning 就是在某一個長度為L, mod k = x 的數字, 加多一個digit [0-9], 變成長度為L+1, mod k = r 的數字, 而上面的說法就是說當x = 0時直接skip, 不要用它來"生成"其它States
去到這兒, 複雜度是 O(N * k * 10) = O(N*k) 還是ok的, 再來看一個完美的圖解
上面代表長度, 下面代表mod k 後的數字...
紅色就是現在iterative的位置, 我們的目標是要加一個數字令到加上 234 mod k = 0
假設我們填了5 吧, 那麼所有 "????5234" 的數字都是答案之一了, 而且我們之後不會再數到suffix = "5234"的數字吧? 所以這兒就要一次過數了
那麼簡單的counting, 我們還有4個位沒有填上, 除了最左的位置之外, 中間所有位置都是任填 [0-9] 就是10 個choice, 最左的位置是9個choice, 所以就是 9*10^(n-3-1-1) * State(4,0)
這樣的想法很對吧? 最後special handle一下 n = 1的case, 因為 suffix不能為0, 而 0 在n = 1時一定會包括的, 那麼 n = 1時把答案減去1 就好了....
然後當然果斷WA了...老實說這樣做連test case #3 也過不了 但確實想不到那兒錯了
看了Editorial, 你他媽的用Top-Down啊...幸好下面comment有人說了bottom-up, 跟我的做法是一樣的說...
連State definition跟公式也都一樣, 細節上例如不用 r = 0 的 state 生成其它state 也都一樣了...
那麼錯什麼呢?
很幸運地, 在昨晚喝了些酒的狀態下終於發現了...我中伏了!
"因為 suffix不能為0, 而 0 在n = 1時一定會包括的, 那麼 n = 1時把答案減去1 就好了...."
這句是bullshit, 完全錯的!
因為不止是n = 1, 事實上不論n是什麼, 要是suffix只有0 mod k = 0, 的話, 不就是 y = 0了嗎?
記得題目條件是 y > 0 的吧....
所以不止是 n = 1時的0 才有問題, 例如k = 3, n = 2, 那麼10也是不行的, 因為唯一mod k = 0的suffix就是0 啊...同理, 30是可以的, 因為除了0之外, 30也是mod k = 0的suffix
考慮了這個原因, 題目又更複雜了...
我也不想大改我的code / state definition
事實上, 那時我才明白為什麼有很多黃字/紅字user的state有3個甚至4個dimensions,
其中一個是 0-1 flag特別處理這個問題的 (就是有沒有suffix 是全部都是0...)
老實說這樣改了State是一定能過的, 但我不想
我也看到有人跟我一樣用2 dimension就過掉了...
於是我想呀想...想到了一個奇怪的點子
這題正常來說, 是Loop完所有state, 最後一次過把r = 0 的states 加起來做答案
而我發現, for 每一個長度 L, dp(L, ?) 只會在那個iterative有用, 之後不會再用到了
然後 0 那個問題, 其實可以想成是 "要是suffix mod k = 0, 那麼我再append 一個0 的時候不要算進答案內"...有點難解釋, 看看state transition吧
State(L, r) --> append 一個digit 變成 --> State(L+1, x),
如果 r 不是0, 那麼沒影響, 原本的算法是正確的
如果 r 是0, 那麼就要看看我append了什麼digit了, 要是digit = 0的話就skip掉吧, 其它digit 就沒影響, 原本算法正確
然後每次iterative完, 直接把答案update! 原因下面解釋
但這樣會把 數個連續是0 的suffix少算了 (eg: ???0000)
但是發現到其實也只是少算了 全部是0 這一個case而已
然後iteration到這一步, r = 0的state已經算進答案了, 該state不會再用到了, 我們直接把dp(L, 0) = 1就好了!
所以其實上述的state transition中, 要是 r = 0, 其實只是代表了suffix全部都是0的數字, 其它令到 r = 0而suffix不是0的, 已經算進答案去了
好吧, 我解釋得很複雜, 因為這題真的很複雜, 很難解釋
我只能說我看到有紅字user 也做了類似的東西, 就是在loop中把state 的value改成1
我說這題不是普通dp是因為, state的意味在中途已經變了...話說這樣的題目, 不論做多少題也沒信心即場一棍過啊...
E: (Graph, Shortest-Path)
一題也是很難, 但不是難在算法, 是難在I/O的問題, 如我說的, 相對題D 真的很易了...
題目給定了一個Graph, 圖中有兩類edge, 一類是完好的路, 一類是破路
求由 s 點到 t 點的最短路的最低cost, cost的算法是: 最短路中"破路數目加上最短路以外的完好路數目"
由於題目很好人的已經告訴你, 最優先條件是最短路, 那找最短路是一定的了
這兒說一下, 由於圖不是weighted, 用BFS也很足夠了 但我心血來潮想用這條題目溫故知新一下Dijkstra Algorithm, 於是寫了兩個version, 兩個都AC了
Dijkstra的確是很易寫也很易明的Algorithm, 不明白為何當年我認為SPFA會更易寫, 比彈性來說Dijkstra絕對較好, 時間也沒很慢 (用Priority Queue的話)
然後..我們來想一下cost 的定義有什麼提示, 隨便寫一下就會發現cost 其實只depends on 完好路的數目 (同理, 其實只depends on 破路的數目, Editorial用前者, 我用後者, 只是Maximize / Minimize的分別)
Dijkstra / BFS的其中一個副作用是, 可以同時找到起點到其它點的最短路
那麼很自然想到可以用一個DFS 作Backtracking, 由終點backtrack到起點, 同時數算(所有)最短路中possible最少破路的數目, 這個Backtrack肯定很快, 因為我們DFS的條件是以該點距離起點的距離 (Dijkstra找出來的)作判定, 要是跟現在的點相差一步才Backtrack的, 基本就是一次DFS的時間吧
去到這兒, 也很順利的, 總共寫了一個Dijkstra/ BFS, 一個DFS, 沒想到 (其實是沒看清楚...)
難處在於I/O...!!!
題目不止要求找出最低Cost...也要找出那些路要修好, 那些路要破壞...!
有見給此, 很自然想到, 在Backtrack時順路把最優最短路整條記下好了
(最優最短路就是令我們有最低cost的最短路)
那麼最優最短路的破路要修好, 最優最短路以外的完好路要破壞!!
這樣問題變成一個最基本的圖論問題了: 如何儲起edge最方便!!!
好吧, 不賣自己關子了, 最好的結論是....溫故知新, 要用上最方便最神的儲圖方法
也就是用 array 做成的adjacency list...
老實說, 溫習後再次發現這個圖的儲法真的很方便, 也很高明
它兼備了adjacency list跟edge list的優點...
int from[200005], to[200005], nxt[200005], adj[200005], w[200005], e = 0;
void add_edge(int a, int b, int type){
from[e] = a; to[e] = b; w[e] = type;
nxt[e] = adj[a];
adj[a] = e++;
}
高明在, 要是edge / vertex有什麼特別的property, 只要再開一條array就可以了..
這題也就這樣了, 但我還是WA了一次
原因也在這個圖的表示方法...!
就是....我開Array開太小了...路是有10^5條, 但是由於是雙向, e 的數目會雙倍啊親...
把array開成2*10^5後就AC了...低級低級錯誤...證明我真的很少用這種表示方式解題啊...
也是一道不錯的題目呢 :)



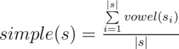
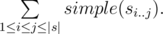

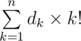 (應該是(k-1)! 才對?)
(應該是(k-1)! 才對?)